
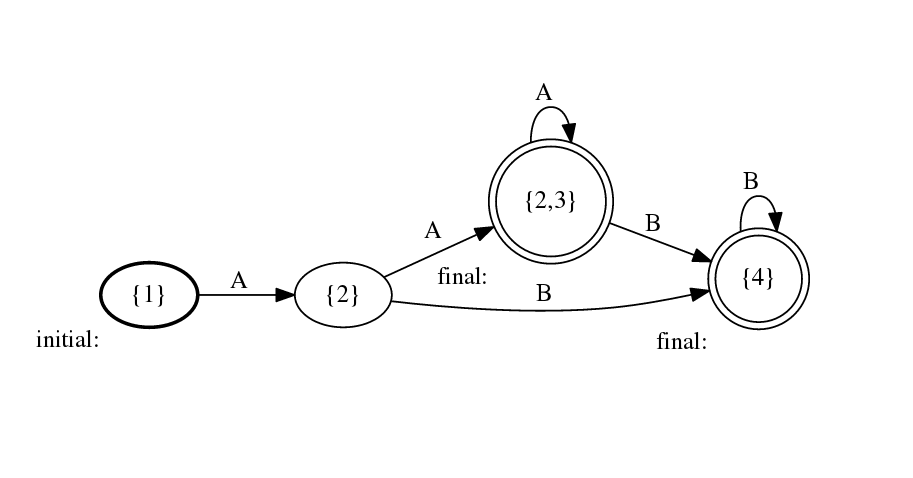
The language is recognized by a relatively simple DFA (attached), so the simplest solution (I think) is to just encode that: module Main where import Text.Parsec import Text.Parsec.String p :: Parser () p = char 'A' >> ((char 'A' >> sA) <|> (char 'B' >> sB)) where sA = (char 'A' >> sA) <|> (char 'B' >> sB) <|> return () sB = (char 'B' >> sB) <|> return () Cheers, Ulrik On 2016-01-24 19:11, Simon Jakobi wrote:
Hi!
I want to test whether a sequence of the characters 'A' and 'B' can represent a sequence of the symbols x and y where x may be represented by one or more 'A's and y may be represented by one or more 'A's or one or more 'B's.
In code, I would like to see the following:
λ> "AABB" `represents` [x, y] True λ> "AA" `represents` [x, y] True
But with my current implementation using attoparsec only the first example works as expected:
import Control.Applicative import Data.Attoparsec.ByteString.Char8 import Data.ByteString import Data.Either import Data.Foldable import Data.Word
type Symbol = Parser [Word8]
x :: Symbol x = many1 (char8 'A')
y :: Symbol y = many1 (char8 'A') <|> many1 (char8 'B')
represents :: ByteString -> [Symbol] -> Bool bs `represents` symbols = isRight $ parseOnly ((sequenceA_ symbols) *> endOfInput) bs
It seems that in "AA" `represents` [x, y] x consumes all the 'A's, leaving none for y.
Is it possible to solve this with attoparsec or are there other parsing libraries that I could use instead?
Cheers, Simon
_______________________________________________ Beginners mailing list Beginners@haskell.org http://mail.haskell.org/cgi-bin/mailman/listinfo/beginners
{kind=link}