Parsing 'A's and then ('A's or 'B's)

Hi! I want to test whether a sequence of the characters 'A' and 'B' can represent a sequence of the symbols x and y where x may be represented by one or more 'A's and y may be represented by one or more 'A's or one or more 'B's. In code, I would like to see the following: λ> "AABB" `represents` [x, y] True λ> "AA" `represents` [x, y] True But with my current implementation using attoparsec only the first example works as expected: import Control.Applicative import Data.Attoparsec.ByteString.Char8 import Data.ByteString import Data.Either import Data.Foldable import Data.Word type Symbol = Parser [Word8] x :: Symbol x = many1 (char8 'A') y :: Symbol y = many1 (char8 'A') <|> many1 (char8 'B') represents :: ByteString -> [Symbol] -> Bool bs `represents` symbols = isRight $ parseOnly ((sequenceA_ symbols) *> endOfInput) bs It seems that in "AA" `represents` [x, y] x consumes all the 'A's, leaving none for y. Is it possible to solve this with attoparsec or are there other parsing libraries that I could use instead? Cheers, Simon

On Sun, Jan 24, 2016 at 07:11:08PM +0100, Simon Jakobi wrote:
I want to test whether a sequence of the characters 'A' and 'B' can represent a sequence of the symbols x and y where x may be represented by one or more 'A's and y may be represented by one or more 'A's or one or more 'B's.
In code, I would like to see the following:
λ> "AABB" `represents` [x, y] True λ> "AA" `represents` [x, y] True
Hello Simon, if I understood your specification correctly, there would be multiple ways to parse the string "AAA": - 3 'x' elements ("A", "A", "A") - 2 'x' elements ("AA", "A") - 2 'x' elements again (first one shorter) ("A", "AA") - 1 'x' element ("AAA") Which of these four should we choose? Maybe "parse as many As as possible without consuming the A followed by a series of B"? If so, a useful combinator is `notFollowedBy` (present in parsec, pretty sure is in attoparsec too, if not it can be easily replicated). Does that help?
Hi Francesco, Thanks for your response!
if I understood your specification correctly, there would be multiple ways to parse the string "AAA":
- 3 'x' elements ("A", "A", "A") - 2 'x' elements ("AA", "A") - 2 'x' elements again (first one shorter) ("A", "AA") - 1 'x' element ("AAA")
There would be even more ways because 'y', too, can represent one or more 'A's. Which of these four should we choose?Maybe "parse as many As as possible
without consuming the A followed by a series of B"?
I don't think that there could be a general rule. For the string "AABB" and the sequence of symbols [x, y, y] there would be two possible parses: [x: "AA", y: "B", y: "B"] or [x: "A", y: "A", y: "BB"]. I only care whether there are any valid parses. I've just tried to solve the problem with regular expressions (using pcre-light) and didn't come across the same problem. Is this due to attoparsec not being able to "backtrack" (not sure if this is the right term)? Is backtracking something that parsers generally are incapable of? Cheers, Simon

If I understood properly,
Have you considered breaking the input into some sort of pattern mask then
validating it?
map (length . group) "AAABB" === [3,2]. Then you can do the same thing
grouping with the target [x, x, y] into [2, 1]. Then you can zip the lists
and ensure the numbers are all smaller than the other respectively. Also,
the lists themselves have the right lengths and order for their elements.
Examples of successful patterns:
[1,1]
AAA,BB
[1, 2]
AAA,B,B
[2,1]
A,AA,BB
AA,A,BB
[2,2]
A,AA,B,B
AA,A,B,B
Try with other examples I think this would work.
On Jan 24, 2016 4:57 PM, "Simon Jakobi"
Hi Francesco,
Thanks for your response!
if I understood your specification correctly, there would be multiple ways to parse the string "AAA":
- 3 'x' elements ("A", "A", "A") - 2 'x' elements ("AA", "A") - 2 'x' elements again (first one shorter) ("A", "AA") - 1 'x' element ("AAA")
There would be even more ways because 'y', too, can represent one or more 'A's.
Which of these four should we choose?Maybe "parse as many As as possible
without consuming the A followed by a series of B"?
I don't think that there could be a general rule.
For the string "AABB" and the sequence of symbols [x, y, y] there would be two possible parses:
[x: "AA", y: "B", y: "B"] or [x: "A", y: "A", y: "BB"].
I only care whether there are any valid parses.
I've just tried to solve the problem with regular expressions (using pcre-light) and didn't come across the same problem. Is this due to attoparsec not being able to "backtrack" (not sure if this is the right term)? Is backtracking something that parsers generally are incapable of?
Cheers, Simon
_______________________________________________ Beginners mailing list Beginners@haskell.org http://mail.haskell.org/cgi-bin/mailman/listinfo/beginners
On Sun, Jan 24, 2016 at 10:56:31PM +0100, Simon Jakobi wrote:
if I understood your specification correctly, there would be multiple ways to parse the string "AAA":
- 3 'x' elements ("A", "A", "A") - 2 'x' elements ("AA", "A") - 2 'x' elements again (first one shorter) ("A", "AA") - 1 'x' element ("AAA")
There would be even more ways because 'y', too, can represent one or more 'A's.
[...]
Is this due to attoparsec not being able to "backtrack" (not sure if this is the right term)? Is backtracking something that parsers generally are incapable of?
Ah, indeed you are right. attoparsec, parsec and friends handle failure with `try`. From Attoparsec documentation: Attempt a parse, but do not consume any input if the parse fails. One way to deal with cases like yours is for every parser to compute a "list of successes". Crude example: import Text.Parsec import Text.Parsec.String foo :: Parser [String] foo = anyChar >>= \h -> (foo <|> e) >>= \t -> return ([""] ++ map (h:) t) where e = return [""] -- λ> parseTest foo "bar" -- ["","b","ba","bar"] Then you can chain those with `try`/`choice` and compute your result(s) (I guess using the list monad to handle the mechanism could do). Ambiguous grammars are an age old problem, and some searching [1] leads me to believe there are already viable solution in Haskell. [1] http://stackoverflow.com/questions/13279087/parser-library-that-can-handle-a...

The language is recognized by a relatively simple DFA (attached), so the simplest solution (I think) is to just encode that: module Main where import Text.Parsec import Text.Parsec.String p :: Parser () p = char 'A' >> ((char 'A' >> sA) <|> (char 'B' >> sB)) where sA = (char 'A' >> sA) <|> (char 'B' >> sB) <|> return () sB = (char 'B' >> sB) <|> return () Cheers, Ulrik On 2016-01-24 19:11, Simon Jakobi wrote:
Hi!
I want to test whether a sequence of the characters 'A' and 'B' can represent a sequence of the symbols x and y where x may be represented by one or more 'A's and y may be represented by one or more 'A's or one or more 'B's.
In code, I would like to see the following:
λ> "AABB" `represents` [x, y] True λ> "AA" `represents` [x, y] True
But with my current implementation using attoparsec only the first example works as expected:
import Control.Applicative import Data.Attoparsec.ByteString.Char8 import Data.ByteString import Data.Either import Data.Foldable import Data.Word
type Symbol = Parser [Word8]
x :: Symbol x = many1 (char8 'A')
y :: Symbol y = many1 (char8 'A') <|> many1 (char8 'B')
represents :: ByteString -> [Symbol] -> Bool bs `represents` symbols = isRight $ parseOnly ((sequenceA_ symbols) *> endOfInput) bs
It seems that in "AA" `represents` [x, y] x consumes all the 'A's, leaving none for y.
Is it possible to solve this with attoparsec or are there other parsing libraries that I could use instead?
Cheers, Simon
_______________________________________________ Beginners mailing list Beginners@haskell.org http://mail.haskell.org/cgi-bin/mailman/listinfo/beginners
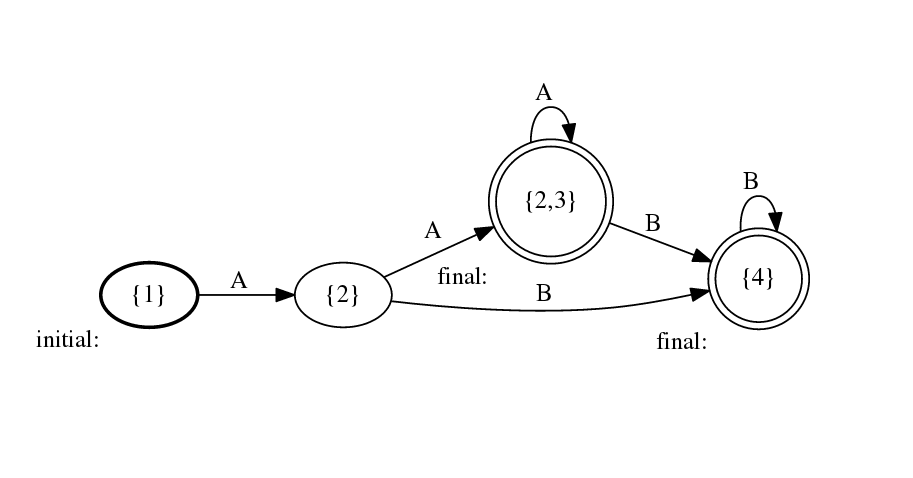{kind=link}
On Wed, Jan 27, 2016 at 01:34:29PM +0100, Ulrik Rasmussen wrote:
The language is recognized by a relatively simple DFA (attached), so the simplest solution (I think) is to just encode that:
module Main where
import Text.Parsec import Text.Parsec.String
p :: Parser () p = char 'A' >> ((char 'A' >> sA) <|> (char 'B' >> sB)) where sA = (char 'A' >> sA) <|> (char 'B' >> sB) <|> return () sB = (char 'B' >> sB) <|> return ()
I am probably missing something: say we have an "AAB" string, how does this check that it is `compatible` with [x,y] or [x,x,y] or [x,y,y] (or not compatible with [x,x,x], etc.)?
On 2016-01-27 13:48, Francesco Ariis wrote:
On Wed, Jan 27, 2016 at 01:34:29PM +0100, Ulrik Rasmussen wrote:
The language is recognized by a relatively simple DFA (attached), so the simplest solution (I think) is to just encode that:
module Main where
import Text.Parsec import Text.Parsec.String
p :: Parser () p = char 'A' >> ((char 'A' >> sA) <|> (char 'B' >> sB)) where sA = (char 'A' >> sA) <|> (char 'B' >> sB) <|> return () sB = (char 'B' >> sB) <|> return ()
I am probably missing something: say we have an "AAB" string, how does this check that it is `compatible` with [x,y] or [x,x,y] or [x,y,y] (or not compatible with [x,x,x], etc.)?
Oh, I read Simon's question as being constrained to the specific problem [x, y] (i.e. recognizing AA*(AA* + BB*)). If the problem is to run any list of parsers such as [x,y,x,x], then this won't work.
participants (4)
-
 Alex Belanger
Alex Belanger -
 Francesco Ariis
Francesco Ariis -
 Simon Jakobi
Simon Jakobi -
 Ulrik Rasmussen
Ulrik Rasmussen