
Salut, récemment j'ai implémenté avec difficulté les polynômes de Lagrange en Haskell. Je pense que je passe à coté d'une écriture beaucoup plus élégante... Comment l'écririez-vous, avec la fameuse notation point-free?? Voici l'équation en annexe... a+ Corentin

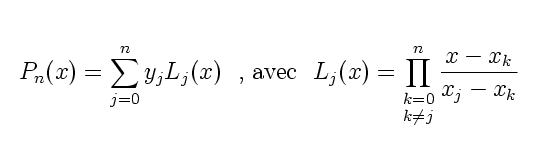{kind=link}

On pourrait toujours procéder à partir de: p ys xs x = zipWith (*) ys . map (flip ($)) x $ ls where ls = ... x .. xs .. mais avant de coder un algorithme inférieur, je cite: Conte and de Boor, "Elementary Numerical Analysis, An Algorithmic Approach", p. 40: "In such a process, use of the Lagrange form seems wasteful since, in calculating p_x(x), no obvious advantage can be taken of the fact that one already has p_k-1(x) available. For this purpose and others, the Newton form of the interpolating polynomial is much better suited." La forme Newton (qui utilise les différences divisées) est beaucoup préférable à celle de Lagrange pour évaluer les polynômes de Lagrange (tu peux la googler plus facilement que je puisse la décrire ici). Dan Weston Dupont Corentin wrote:
Salut, récemment j'ai implémenté avec difficulté les polynômes de Lagrange en Haskell. Je pense que je passe à coté d'une écriture beaucoup plus élégante... Comment l'écririez-vous, avec la fameuse notation point-free??
Voici l'équation en annexe...
a+ Corentin
------------------------------------------------------------------------
------------------------------------------------------------------------
_______________________________________________ Haskell-fr mailing list Haskell-fr@haskell.org http://www.haskell.org/mailman/listinfo/haskell-fr
A quoi sert le $ dans ta formule? On 9/24/07, Dan Weston <westondan@imageworks.com> wrote:
On pourrait toujours procéder à partir de:
p ys xs x = zipWith (*) ys . map (flip ($)) x $ ls where ls = ... x .. xs ..
mais avant de coder un algorithme inférieur, je cite:
Conte and de Boor, "Elementary Numerical Analysis, An Algorithmic Approach", p. 40:
"In such a process, use of the Lagrange form seems wasteful since, in calculating p_x(x), no obvious advantage can be taken of the fact that one already has p_k-1(x) available. For this purpose and others, the Newton form of the interpolating polynomial is much better suited."
La forme Newton (qui utilise les différences divisées) est beaucoup préférable à celle de Lagrange pour évaluer les polynômes de Lagrange (tu peux la googler plus facilement que je puisse la décrire ici).
Dan Weston
Dupont Corentin wrote:
Salut, récemment j'ai implémenté avec difficulté les polynômes de Lagrange en Haskell. Je pense que je passe à coté d'une écriture beaucoup plus élégante... Comment l'écririez-vous, avec la fameuse notation point-free??
Voici l'équation en annexe...
a+ Corentin
------------------------------------------------------------------------
------------------------------------------------------------------------
_______________________________________________ Haskell-fr mailing list Haskell-fr@haskell.org http://www.haskell.org/mailman/listinfo/haskell-fr
_______________________________________________ Haskell-fr mailing list Haskell-fr@haskell.org http://www.haskell.org/mailman/listinfo/haskell-fr
L'opérateur ($) n'est que l'application (d'une fonction) à basse précédence, dont la définition est assez simple: infixr 0 $ f $ x = f x C'est la première ligne qui coûte. La précédence de l'application est 10 (la plus haute), tandis que la précédence de ($) est 0 (la plus basse). E.g., f . g . h . k $ x = f (g (h (k x))) ($) sert à obvier aux parenthèses et à un style point-free qui est (pour moi au moins) plus compréhensible et élégant, mais tous les deux sont traduits identiquement. Dan Dupont Corentin wrote:
A quoi sert le $ dans ta formule?
On 9/24/07, *Dan Weston* <westondan@imageworks.com <mailto:westondan@imageworks.com>> wrote:
On pourrait toujours procéder à partir de:
p ys xs x = zipWith (*) ys . map (flip ($)) x $ ls where ls = ... x .. xs ..
mais avant de coder un algorithme inférieur, je cite:
Conte and de Boor, "Elementary Numerical Analysis, An Algorithmic Approach", p. 40:
"In such a process, use of the Lagrange form seems wasteful since, in calculating p_x(x), no obvious advantage can be taken of the fact that one already has p_k-1(x) available. For this purpose and others, the Newton form of the interpolating polynomial is much better suited."
La forme Newton (qui utilise les différences divisées) est beaucoup préférable à celle de Lagrange pour évaluer les polynômes de Lagrange (tu peux la googler plus facilement que je puisse la décrire ici).
Dan Weston
Dupont Corentin wrote: > Salut, > récemment j'ai implémenté avec difficulté les polynômes de Lagrange en > Haskell. > Je pense que je passe à coté d'une écriture beaucoup plus élégante... > Comment l'écririez-vous, avec la fameuse notation point-free?? > > Voici l'équation en annexe... > > a+ > Corentin > > > ------------------------------------------------------------------------
> > > ------------------------------------------------------------------------ > > _______________________________________________ > Haskell-fr mailing list > Haskell-fr@haskell.org <mailto:Haskell-fr@haskell.org> > http://www.haskell.org/mailman/listinfo/haskell-fr
_______________________________________________ Haskell-fr mailing list Haskell-fr@haskell.org <mailto:Haskell-fr@haskell.org> http://www.haskell.org/mailman/listinfo/haskell-fr
------------------------------------------------------------------------
_______________________________________________ Haskell-fr mailing list Haskell-fr@haskell.org http://www.haskell.org/mailman/listinfo/haskell-fr

Le mardi 25 septembre 2007, Dan Weston a écrit :
L'opérateur ($) n'est que l'application (d'une fonction) à basse précédence, dont la définition est assez simple:
infixr 0 $ f $ x = f x
C'est la première ligne qui coûte. La précédence de l'application est 10 (la plus haute), tandis que la précédence de ($) est 0 (la plus basse).
E.g., f . g . h . k $ x = f (g (h (k x)))
($) sert à obvier aux parenthèses et à un style point-free qui est (pour moi au moins) plus compréhensible et élégant, mais tous les deux sont traduits identiquement.
Si je peux me permettre, je vais donner un exemple extrémement simple: addition a b = a + b addition a addition c d Sur cette deuxième ligne, haskell va râler du style "addition prends 2 arguments, pas 4". Le '$' permet d'écrire: addition a $ addition b c on a alors "a" et "addition b c", ce qui ne fait plus que deux argument au premier "addition". Le '.' j'ai encore du mal ;)
addition a $ addition b c
Aussi on voit parfois addition a $ addition b $ c Ce dernier dépend de ce que le ($) s'associe vers la droite, fixé dans le Prélude par le r à la fin de infixr, parsé comme: addition a $ (addition b $ c) Le plus souvent, je vois addition a . addition b $ c Ce dépend de ce que le ($) a une précédence inférieure à celle de (.), fixée à 9 dans le Prélude par "infixr 9 .", parsé comme: (addition a . addition) b $ c Enfin, il faut trouver un style qui te conviennes et y tenir. Moi, je préfère ce dernier. Dan Olivier Thauvin wrote:
Le mardi 25 septembre 2007, Dan Weston a écrit :
L'opérateur ($) n'est que l'application (d'une fonction) à basse précédence, dont la définition est assez simple:
infixr 0 $ f $ x = f x
C'est la première ligne qui coûte. La précédence de l'application est 10 (la plus haute), tandis que la précédence de ($) est 0 (la plus basse).
E.g., f . g . h . k $ x = f (g (h (k x)))
($) sert à obvier aux parenthèses et à un style point-free qui est (pour moi au moins) plus compréhensible et élégant, mais tous les deux sont traduits identiquement.
Si je peux me permettre, je vais donner un exemple extrémement simple:
addition a b = a + b
addition a addition c d
Sur cette deuxième ligne, haskell va râler du style "addition prends 2 arguments, pas 4". Le '$' permet d'écrire:
addition a $ addition b c
on a alors "a" et "addition b c", ce qui ne fait plus que deux argument au premier "addition".
Le '.' j'ai encore du mal ;)
------------------------------------------------------------------------
_______________________________________________ Haskell-fr mailing list Haskell-fr@haskell.org http://www.haskell.org/mailman/listinfo/haskell-fr
Ce dépend de ce que le ($) a une précédence inférieure à celle de (.), fixée à 9 dans le Prélude par "infixr 9 .", parsé comme:
(addition a . addition) b $ c
Evidemment je voulais écrire:
(addition a . addition b) $ c
Dan Weston wrote:
addition a $ addition b c
Aussi on voit parfois
addition a $ addition b $ c
Ce dernier dépend de ce que le ($) s'associe vers la droite, fixé dans le Prélude par le r à la fin de infixr, parsé comme:
addition a $ (addition b $ c)
Le plus souvent, je vois
addition a . addition b $ c
Ce dépend de ce que le ($) a une précédence inférieure à celle de (.), fixée à 9 dans le Prélude par "infixr 9 .", parsé comme:
(addition a . addition) b $ c
Enfin, il faut trouver un style qui te conviennes et y tenir. Moi, je préfère ce dernier.
Dan
Olivier Thauvin wrote:
Le mardi 25 septembre 2007, Dan Weston a écrit :
L'opérateur ($) n'est que l'application (d'une fonction) à basse précédence, dont la définition est assez simple:
infixr 0 $ f $ x = f x
C'est la première ligne qui coûte. La précédence de l'application est 10 (la plus haute), tandis que la précédence de ($) est 0 (la plus basse).
E.g., f . g . h . k $ x = f (g (h (k x)))
($) sert à obvier aux parenthèses et à un style point-free qui est (pour moi au moins) plus compréhensible et élégant, mais tous les deux sont traduits identiquement.
Si je peux me permettre, je vais donner un exemple extrémement simple:
addition a b = a + b
addition a addition c d
Sur cette deuxième ligne, haskell va râler du style "addition prends 2 arguments, pas 4". Le '$' permet d'écrire:
addition a $ addition b c
on a alors "a" et "addition b c", ce qui ne fait plus que deux argument au premier "addition".
Le '.' j'ai encore du mal ;)
------------------------------------------------------------------------
_______________________________________________ Haskell-fr mailing list Haskell-fr@haskell.org http://www.haskell.org/mailman/listinfo/haskell-fr
participants (4)
-
 Dan Weston
Dan Weston -
 david48
david48 -
 Dupont Corentin
Dupont Corentin -
 Olivier Thauvin
Olivier Thauvin