
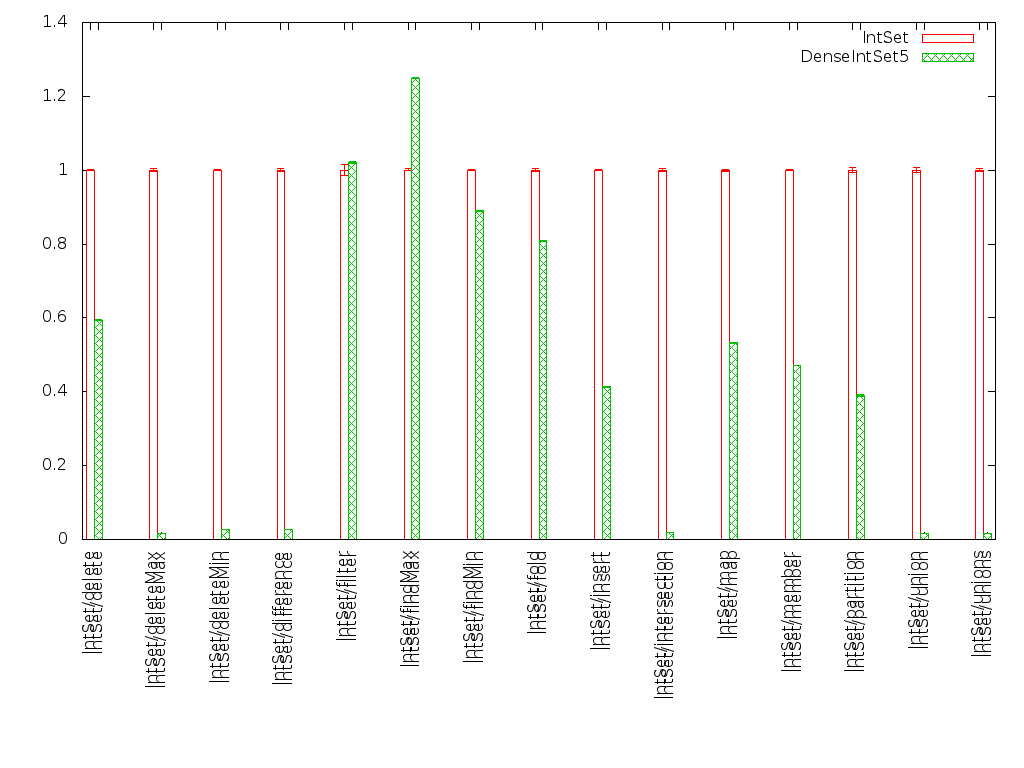
Hi, for one of my applications, I am generating huge IntSets (and IntMaps), and I am regularly hitting the memory constraints of my machine. Hence I am looking for a better implementation of IntSets with smaller memory foot print, at least in the case of dense sets, e.g. those where it is likely that a few values are equal in all but the lower 5 or 6 bits. So instead of a simple tree, I re-implemented IntSet as a tree where the nodes contain bit maps of one machine word (32 or 64 entries): Instead of Data.IntSet> putStr $ showTree $ fromList [-3, -1,1,2,42,100] * +--* | +--* | | +--* | | | +-- 1 | | | +-- 2 | | +-- 42 | +-- 100 +--* +-- -3 +-- -1 we have Data.DenesIntSet> putStr $ showTree $ fromList [-3, -1,1,2,42,100] * +--* | +-- 0 0000000000000000000001000000000000000000000000000000000000000110 | +-- 64 0000000000000000000000000001000000000000000000000000000000000000 +-- -64 1010000000000000000000000000000000000000000000000000000000000000 The results are promising. I have attached a "progress" graph, comparing the performance of IntMap with DenseIntMap. As you can see, performance is better for most common operations, greatly better for intersection and union, and comparable for fold/filter/findMax/findMin. And here is the memory usage of an IntSet with one million members and varying distance between the entries: $ cat membench.hs import qualified Data.IntSet as S import qualified Data.DenseIntSet as DS import System.Environment main = do [what, sizeS, stepS] <- getArgs let list = [0,read stepS .. read stepS * read sizeS] if what `elem` ["r","R"] then S.size ( S.fromList list) `seq` return () else DS.size (DS.fromList list) `seq` return () For IntSet, the memory consumption does not change notably with the step size: $ ./membench +RTS -t -RTS r 1000000 1 2>&1 | perl -n -e '/, (\d+M) in use/ && print "$1\n"' 80M $ ./membench +RTS -t -RTS r 1000000 2 2>&1 | perl -n -e '/, (\d+M) in use/ && print "$1\n"' 80M $ ./membench +RTS -t -RTS r 1000000 10 2>&1 | perl -n -e '/, (\d+M) in use/ && print "$1\n"' 79M $ ./membench +RTS -t -RTS r 1000000 100 2>&1 | perl -n -e '/, (\d+M) in use/ && print "$1\n"' 79M But for DenseIntMap, we see that dense maps are, as desired, much more compact: $ ./membench +RTS -t -RTS d 1000000 1 2>&1 | perl -n -e '/, (\d+M) in use/ && print "$1\n"' 2M $ ./membench +RTS -t -RTS d 1000000 2 2>&1 | perl -n -e '/, (\d+M) in use/ && print "$1\n"' 3M $ ./membench +RTS -t -RTS d 1000000 10 2>&1 | perl -n -e '/, (\d+M) in use/ && print "$1\n"' 18M $ ./membench +RTS -t -RTS d 1000000 100 2>&1 | perl -n -e '/, (\d+M) in use/ && print "$1\n"' 77M I have put the code here: https://github.com/nomeata/containers/blob/denseintmap/Data/DenseIntSet.hs It certainly needs a bit more cleanup, e.g. documenting, commenting and maybe improving the test coverage (as, after all, I added quite a bit of logic that can now go wrong). And I did not test the code on a 32 bit system yet. But I’d like to hear from you whether this could in principle go into the containers library (as IntSet, not as DenseIntSet) or if there is a reason not to use this implementation. Thanks, Joachim -- Joachim "nomeata" Breitner mail@joachim-breitner.de | nomeata@debian.org | GPG: 0x4743206C xmpp: nomeata@joachim-breitner.de | http://www.joachim-breitner.de/
{kind=link}