
Hi, Am Sonntag, den 18.09.2011, 22:47 +0200 schrieb Joachim Breitner:
I’d like to avoid the binary search, as it is more expensive for dense sets. Milan’s suggestion of shifts by 6 might be a good compromise. Another approach might be to first use lowestBitSet to start with the lowest bit. In case of only one bit set, it will not iterate further then.
I tried adding some strictness annotation to go and see if that helps. According to the attachement, it does, instead of 4 times slower in the worst case (Size 4 million, step 100) it is only ~2,2x slower.
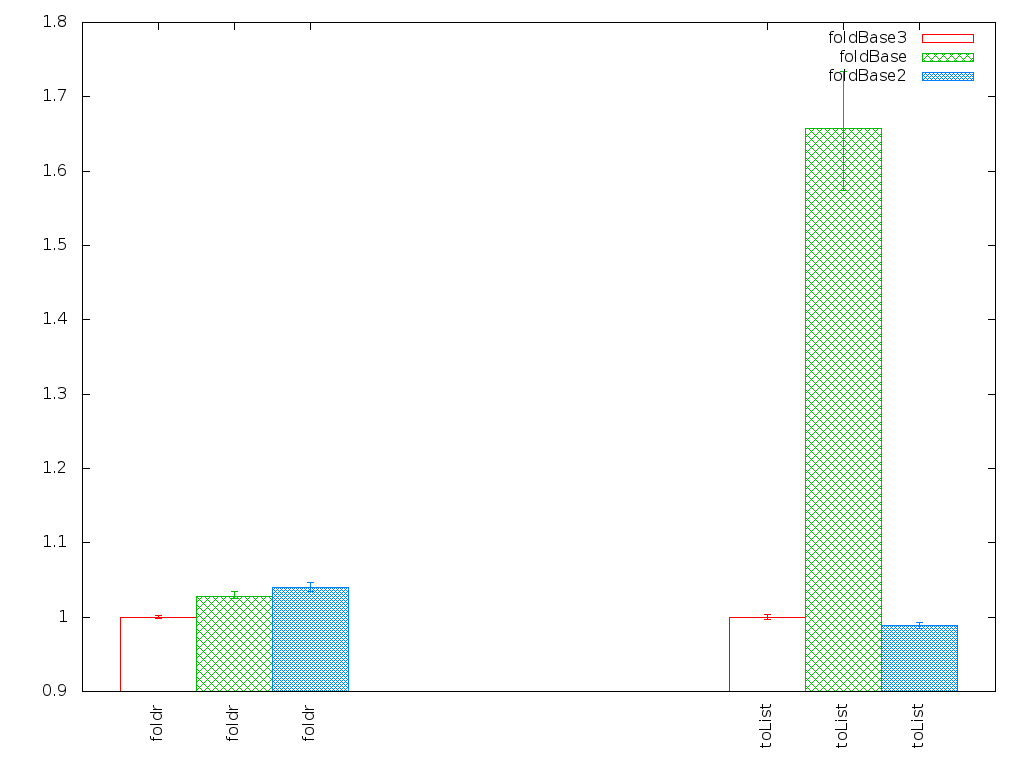
first shifting by lowestBitSet seems to help noticably, at least in my benchmarks, see attachment. Slowdown in the worst case is only 1.25 by now. That is enough for today, the benchmarks take too long and it is late :-) lowestSetBit could maybe be optimized further. There seems to be an operation for that (bsr and bsf), it remains to be checked if this is sufficiently fast. If it is indeed, then this should indeed by done inside the loop, and not just one, as Henning suggests. Can library code easily call such primitive ops directly or would that require support in GHC? Changing succ bi to bi + 1 (not included in attached benchmark yet) seems to have a minor benefit on a pure foldrBits benchmark and a minor degression on a pure toList benchmark (see plot.png) Not sure what that means, probably nothing.
You could improve the two Bin vs Tip cases. When you are in that case, call a function 'lookupTip'...
I’ll do the intersection optimization, although I wonder if ghc would not do that for me if it were allowed to introduce enough call patterns? Good night for now Joachim -- Joachim "nomeata" Breitner mail@joachim-breitner.de | nomeata@debian.org | GPG: 0x4743206C xmpp: nomeata@joachim-breitner.de | http://www.joachim-breitner.de/
{kind=link}